
Notes on LLM RecSys Product – Edition 3 of a newsletter focused on building LLM powered products.
Eval-first product building is having a moment. We all know we should run evals, ship evals, and just do more evals.
But evals are just snapshots – moments in time when you check if something works. The real breakthrough isn’t running evaluations. It’s building the evaluation loop – the end-to-end system that diagnoses continuously, improves deliberately, and makes probabilistic systems governable.
From Self-Awareness to Action
In the last post, I wrote about teacher models giving us painful self-awareness – you can evaluate millions of outputs and know what’s broken at scale. The eval loop is what you DO with that awareness: a continuous diagnostic and improvement system that makes LLM-powered products actually improvable.
In deterministic products, the process used to be: Ship → Monitor engagement → Small-batch human reviews when something breaks. Feedback was slow and sparse. In LLM recsys products, the eval loop runs continuously.
The Eval Loop
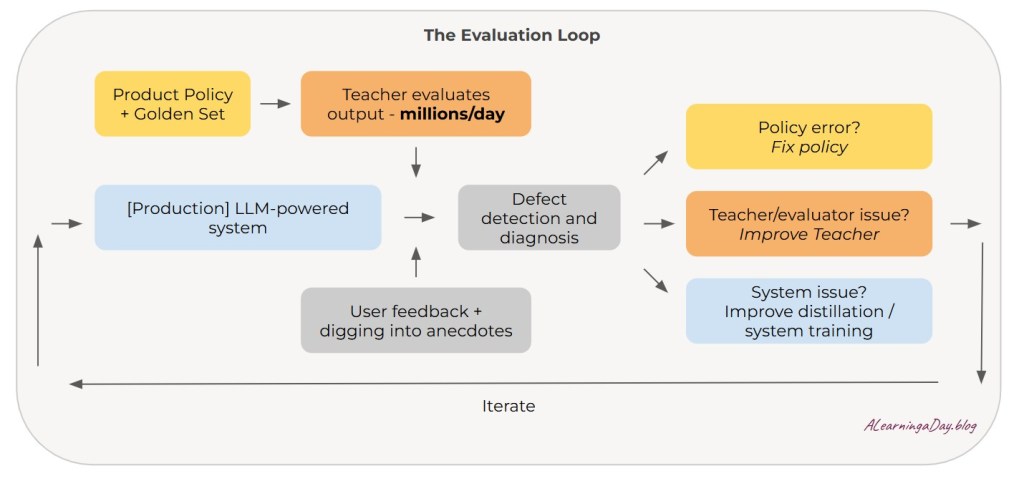
Here’s how it works:
- The Product Policy defines what “good” looks like – the criteria, constraints, and guardrails for how the system should behave – including a “Golden Set” of high-quality examples.
- This trains the Teacher Model, your evaluator.
- The production Stack generates outputs in response to real user interactions. The Teacher continuously evaluates these outputs at a scale of millions per day.
- We also meld user feedback and investigation into anecdotal issues/data to surface more defects.
This surfacing of defects at scale leads to Diagnosis where failure points to one of three places:
- Policy problem – We didn’t define “good” clearly enough. The rubric is incomplete or wrong.
- Teacher problem – Our evaluator itself is broken. It’s judging incorrectly.
- Distillation problem – The production model hasn’t learned what the teacher knows. Training data or model capacity is the bottleneck.
The fix flows back into the system – refine policy, improve the teacher, update training data – and the loop continues.
Unlocking velocity and shifting measurement
The loop unlocks velocity by operating on two planes simultaneously:
- Online: The teacher judges live production outputs continuously. You know what’s breaking in real-time, not weeks later through support tickets or engagement dips.
- Offline: Before shipping any change, you can test it against the teacher. Run it through thousands of test cases. See how eval metrics move. Fail fast without running live experiments on real users.
In deterministic products, we measured outcome metrics: clicks, retention, revenue. In LLM recsys products, these are lagging indicators. The eval loop runs on quality metrics – leading indicators judged by your teacher.
Quality metrics thus guide daily improvement. Outcome metrics tell you if that improvement matters.
The Loop Is The Mechanism
In deterministic products, you improved by changing code. You wrote a new feature, shipped it, measured engagement.
In LLM recsys products, you improve by running the evaluation loop first. You can’t fully specify the system’s behavior upfront – it’s probabilistic. The loop is how you systematically improve something you can’t completely control.
Once again, adding an LLM into your system isn’t a panacea. You’ll be limited in production by latency and cost – so, the eval loop is the only way to build products around models that are powerful but imperfect, capable but costly, impressive in demos but messy at scale.
Next: The eval loop only works if your teacher knows what “good” looks like. That’s where we’re going next.
PS: A quick note on eval suites: As your product matures, you’ll likely move from one teacher to multiple – separate evaluators for various dimensions of the product. The same principle scales. Each evaluator judges a specific dimension, all feeding into the same diagnostic loop.
