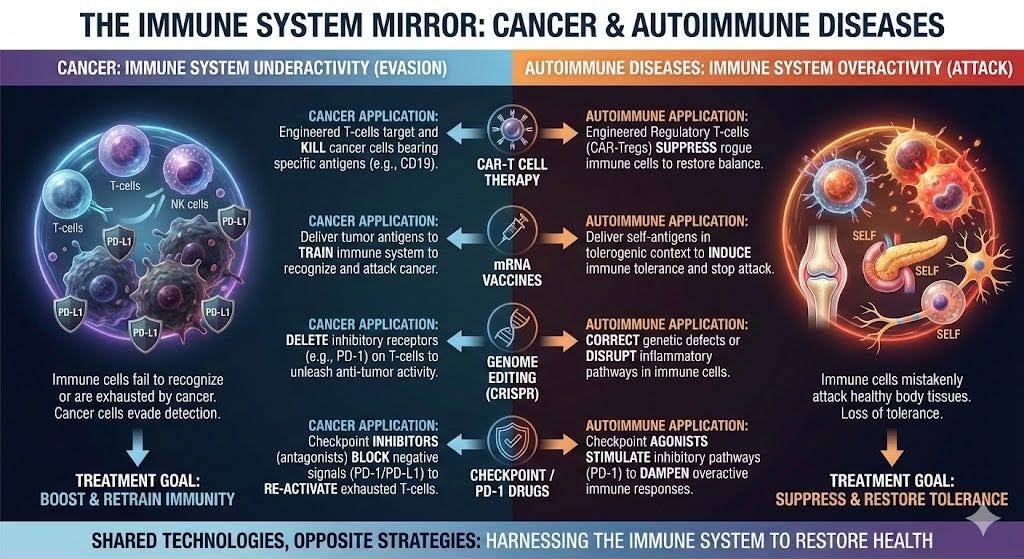
Dr Eric Topol had a fascinating post on his blog about a potential massive change in the treatment of Autoimmune diseases. I can’t claim to have understood all the biology nuances but I did love the following –
(1) 10% of the world’s population suffers from autoimmune diseases and these have, so far, had no cure.
(2) He goes on to explain an approach that uses inverse vaccines. So, instead of vaccines boosting the immune system, these inverse vaccines do the opposite.
(3) But, most interesting, is the fact that these diseases are the mirror image of cancer. So, while cancer causes us to lose all immunity, these result in hyperactive immune responses. So, all the progress in treating cancer with the breakthroughs in the past two decades – including mRNA vaccines and CRISPR – results in progress in treating autoimmune diseases by doing the opposite.
He closes with these concluding remarks
I hope I am able to adequately convey the excitement in this field. This represents one of the biggest shifts in a domain of medicine that we’ve seen in decades. It has been stunning to see for the first time one-shot cures in patients who were refractory to all approved treatments. There’s a paucity of true cures in medicine. Considering that 1 in 10 people have an autoimmune disease, and these conditions have never garnered the level of attention as cancer, cardiovascular, or neurodegenerative diseases, these big steps of progress are especially welcome. Mirror biology and goals of all the clinical work in cancer directly benefits autoimmune diseases, turbocharging this movement.
It’s still early, but most major autoimmune diseases are getting approached by both the engineered cell and inverse, tolerogenic vaccines. The off-the-shelf, universal engineered cell approach is ahead of the inverse vaccines so far, and the refinements in the work are extensive. Eventually, both major routes of cell therapy and tolerogenicity are very likely to pan out and we should see a big dent in autoimmune diseases in the future. Of course, for any scaling, this will require availability at low cost, limiting side effects, making in practical and accessibility to all, avoiding inequities. But given all the rapid progress I’m confident we’ll get there in the years ahead.We’re seeing the initial stages of a renaissance vs autoimmunity. Curinginstead of just treating autoimmune diseases.
He brings together some powerful data about how young men are spending more of their time alone.
And then goes to share stories of two men – who are part of this large group – who are spending significant time during this loneliness either on porn or gambling. There’s even a term for those focused on porn – gooners.
As the journalist Kolitz wrote in his chilling and spectacular essay in Harper’s Magazine, gooning is a ”new kind of masturbation” that has gained popularity among young men around the world. Its practitioners spend hours or days at a time “repeatedly bringing [themselves] to the point of climax … to reach the goonstate’: a supposed zone of total ego death or bliss that some liken to advanced meditation.”
He goes on to frame this as an “absence-of-loneliness” crisis.
While I know that some men are lonely, I do not think that what afflicts America’s young today can be properly called a loneliness crisis. It seems more to me like an absence-of-loneliness crisis. It is a being-consantly-alone-and-not-even-thinking-that’s-a-problem crisis. Americans—and young men, especially—are choosing to spend historic gobs of time by themselves without feeling the internal cue to go be with other people, because it has simply gotten too pleasurable to exist without them.
After examining the rise of gambling (hence the casino), his conclusion is poignant.
This inversion of risk doesn’t come out of nowhere. It’s the predictable result of how public policy and technological change have allocated risk and reward. Since the 1970s, America has over-regulated the physical world and under-regulated the digital space. To open a daycare, build an apartment, or start a factory requires lawyers, permits, and years of compliance. To open a casino app or launch a speculative token requires a credit card and a few clicks. We made it hard to build physical-world communities and easy to build online casinos. The state that once poured concrete for public parks now licenses gambling platforms. The country that regulates a lemonade stand will let an 18-year-old day-trade options on his phone.
In short: The first half of the twentieth century was about mastering the physical world, the first half of the twenty-first has been about escaping it.
This shift has moral as well as economic consequences. When a society pushes its citizens to take only financial risks, it hollows out the virtues that once made collective life possible: trust, curiosity, generosity, forgiveness. If you want two people who disagree to actually talk to each other, you build them a space to talk. If you want them to hate each other, you give them a phone.
It is a rotten game that we’ve signed up to play together, and somewhere deep down, beneath the whirl of dopamine that traps us in dark places, I think we know that a better game exists. Porn may be compulsive, and gambling may be a blast, but I refuse to believe that blasting ourselves with compulsion is the end state of human progress. The alternative is staring us in the face, and like most true things, it is obvious but not simple. The game is being alive. It comes with tears and boredom and disappointments and deep, deep joy. It is meant to be played in the sun and in the shadows cast by other people.
I book a lot of travel through Chase Travel, and many of those flights end up being on United. Every once in a while, I get an an email titled – “Urgent – Your itinerary has been updated.”
Except the message never actually tells me what changed.
So I end up comparing the old itinerary with the new one – flight numbers, timings, connections – trying to spot a difference that isn’t always obvious. In some cases, I never figure it out. Maybe it was a terms-and-conditions tweak. Maybe a backend update. Who knows.
As someone who receives a lot of harsh criticism about the products I’ve built over the years, I always remind myself it’s far easier to criticize than it is to build. I’m sure there’s some operational or technical reason things work this way.
But it’s still a good reminder for anyone building products – and especially for myself: If you notify a user that something changed, make it dead easy to find the change.
A simple visual cue or one clear line of copy can transform an experience.
I was in a situation recently where I found myself reflecting on the repercussions of something I signed without giving it enough thought.
I can think of a couple such examples over the years that have cost me a fair bit of money in retrospect.
One of them involved lessons about trust – the kind you only learn by living through them.
But another was far simpler: I just didn’t weigh what I signed carefully enough.
Take the time to think it through and ask your questions. In the best-case, it was just a bit of extra time. And in the worst case, you just saved yourself a lot of money and hassle.
Notes on LLM RecSys Product – Edition 2 of a newsletter focused on building LLM powered products.
The central thesis of this newsletter is that we are moving from deterministic workflows to model-centered products – products built around LLM-powered recommender systems as the core primitive.
We’re not fully in that future yet. Most AI products today are still tools that tackle narrow use cases better – generate text, summarize content, answer questions. They are improvements, but they are not yet systems that help people get things done.
Still, the direction of change is clear. As model capabilities continue to improve, user expectations will shift across domains – writing, presentations, job search, customer support -from “give me the tool” to “help me make progress.”
That is the real promise of agents and applied AI products. Not magical autonomy, but systems that understand context, infer intent, and assist meaningfully. In other words, they will need a recommender system at the core.
But not the recommender systems we’re used to. Especially because the open question this creates is how to build predictable, trustworthy systems when the output is inherently probabilistic.
Why traditional recommender systems break
For years, recommender systems were constrained in two fundamental ways.
First, they relied on structured data and fixed taxonomies. They required predefined taxonomies and candidate sets, even though real product data – messages, resumes, notes, goals, intent – is overwhelmingly unstructured.
Second, they were black boxes steered by blunt reward functions. Behavior was optimized indirectly through metrics like clicks, dwell time, or engagement. Improving the system meant tweaking the reward, not improving understanding or reasoning.
That architecture was sufficient for optimizing engagement. It is poorly suited for helping users achieve goals.
LLM-powered recommender systems are semantic and teacher-supervised
The breakthrough in LLM-powered recommender systems isn’t simply replacing parts of the old stack with LLMs. It’s the combination of semantic understanding with teacher supervision.
LLMs can ingest and produce semantic input and output, reason over unstructured data, and operate across large context windows. That dramatically expands what recommender systems can do. While this dramatically improves capability, it still leaves blind spots: when does the system work, when does it fail, and why?
The breakthrough is our ability to pair production models with a high-quality “teacher model” – a large model used to evaluate outputs at scale. This teacher is too expensive to run in the critical path, but ideal for judging behavior, surfacing errors, and identifying quality gaps.
This structure creates two powerful improvement levers:
Improve the teacher → the system’s judgment gets sharper
Improve the training data → production models inherit this better judgment.
The introduction of the teacher makes the system self-aware and coachable. Instead of guessing whether the system is improving, you can now see it. In sum, LLMs with semantic understanding give your stack capability, but the teacher model enables governance.
The demo–to–production gap: cost makes your system imperfect but self-aware and coachable
This is also the point where demos and real products diverge.
In a demo, you can run a large, frontier model on every request and get something that looks magical. At scale, that approach collapses quickly under latency and GPU cost. The moment you ship to production, you’re forced to use smaller, cheaper models to keep the system fast and scalable.
And that’s when imperfection shows up. As costs come down, different parts of the stack start making mistakes that weren’t visible in that demo. Your production grade AI-powered system is noticeably imperfect.
That’s the bad news.
From stumbling in the dark to painful self-awareness
The good news is that teacher supervision turns imperfection into something you can work with.
Before teacher-supervised systems, building AI products felt like stumbling in the dark. Teams relied on coarse engagement metrics and small-scale human review to infer how models behaved.
With a teacher model, teams live in painful self-awareness.
You can now evaluate millions of outputs every day. You will know what’s wrong at scale, where it’s wrong, and why. The reason this self-awareness is painful is because you won’t be able to fix everything immediately – cost, latency, and model size constraints are very real – but you can work deliberately, one acute failure mode at a time.
That is the shift: from chasing metrics to diagnosing behavior, from intuition to evaluation, from shiny demos to systems that can actually improve. To be clear: teacher models aren’t ground truth. They’re probabilistic judges that must be anchored in human judgment and long-term outcomes. Their value isn’t correctness, but making evaluation continuous, scalable, and unavoidable.
Evaluation is the mechanism that makes outcome-oriented, probabilistic systems tractable under real-world constraints – and the foundation for how AI-native teams will operate going forward.
All of this brings us to two counter-intuitive takeaways –
(1) Existing recommender systems are deeply limited in many ways. But the magic moment doesn’t arrive when you replace them with LLM-powered recommender systems. As soon as you confront scaling costs, you’re forced to use cheaper, imperfect models. This is where reality cuts differently from the shiny demo.
(2) Semantic models unlock capability, but teacher supervision unlocks governance. LLMs make systems powerful, evaluation makes them understandable and improvable. And while the system might be imperfect, a teacher model enables painful self-awareness and coachability – the kind that reveals problems at scale and lets teams improve deliberately, one acute failure mode at a time.
That sets us up for the next edition – building painful self-awareness and coachability via the evaluation loop.
If you can’t engage with patience and focus, don’t engage at all.
A half-hearted engagement often causes more damage than no engagement. It is nearly always better to pause, reset, and return with intention than to show up distracted and reactive.
In most situations, the quality of our presence matters more than the speed of our response.
There’s an insightful story Jack Welch often told about a formative moment early in his career at GE. He was part of a graduate program with a cohort of new hires – a mix of people who worked hard and carried their weight, and others who clearly did not.
During performance review time, he learned that everyone in the program was being given the same raise.
He was furious because he knew who in the group was doing exceptional work and who wasn’t. Everyone did. As he put it, “Kids in any class know who the best students are.”
Effort and performance aren’t as subjective as we sometimes pretend.
That moment shaped him. It became the seed for his later, legendary emphasis on meritocracy at GE – including the (controversial) forced ranking system where the bottom 10% were consistently shown the door.
Agree or disagree with the method, the underlying principle he lived by was clear: When you reward strong performance, people rise to the standard. And when you tolerate weak performance – or worse, reward it – you destroy accountability.
And when accountability disappears, the people who thrive on it leave.
In many ways, that is the beginning of the end for any high-performing team or organization.